
Welcome to our comprehensive web scraping guide, where you’ll learn the ins and outs of extracting valuable data from websites. In today’s digital age, mastering data extraction techniques is vital for businesses and researchers alike. This guide will introduce you to Python web scraping, a powerful method that simplifies the process of pulling information from online sources. Alongside the best web scraping tools and best practices, we’ll provide you with step-by-step instructions on how to scrape websites effectively and ethically. Whether you’re a beginner or an experienced coder, understanding these techniques will empower you to harness the vast information available on the internet.
In this tutorial on web data extraction, we will delve into the different methodologies and tools available to gather and analyze information from various online platforms. Understanding how to extract data, known as web harvesting, is essential for anyone looking to leverage online resources for business intelligence or research. Throughout this discussion, we will cover essential topics such as advanced data scraping methods using programming languages like Python, along with recommended software solutions that can automate the scraping process. Additionally, we will explore some effective strategies to ensure your scraping practices are aligned with current ethical standards and best practices. Prepare to unlock a treasure trove of insights with our guide to efficient website data collection!
Understanding Web Scraping Basics
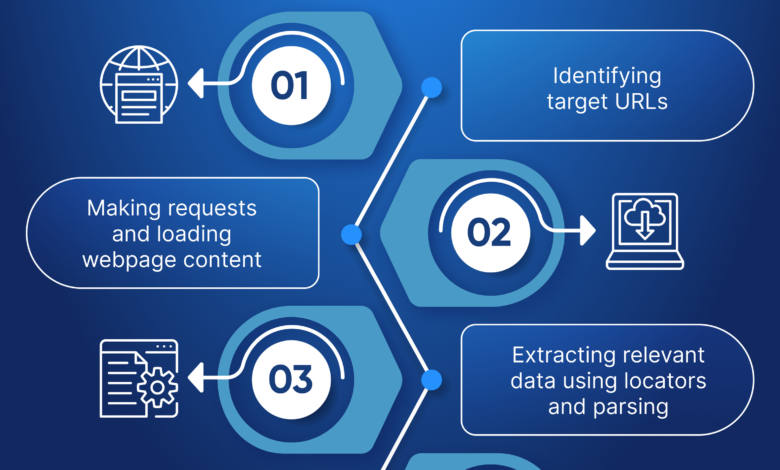
Web scraping is an automated method used for extracting large amounts of data from websites. It enables users to gather data effectively from various sources, making it an invaluable technique for researchers, marketers, and businesses. To start, it’s important to understand the basic concepts such as HTTP requests, HTML structure, and how to navigate the DOM (Document Object Model) of a webpage. This foundational knowledge is crucial for anyone looking to master data extraction techniques.
Additionally, web scraping best practices should be considered to avoid getting blocked by websites. This includes respecting the website’s terms of service, employing proper headers, and implementing rate limiting in your scripts. Understanding how to identify and manipulate data from websites through these best practices ensures a smoother scraping process while maximizing data usability.
Getting Started with Python Web Scraping
Python has become a go-to language for web scraping due to its powerful libraries and ease of use. Libraries like BeautifulSoup, Scrapy, and Requests facilitate libraries for navigating HTML, sending requests, and parsing data efficiently. To scrape a website, you first need to install these libraries, and then you can write a script to extract data by targeting specific HTML elements. Learning the syntax and methods used in these libraries will significantly streamline the data gathering process.
Creating a simple web scraping script in Python can yield immediate results. For example, you can quickly write a few lines of code to scrape product prices from an eCommerce site. Once you understand the basic structure of a script, you can adapt it to collect various types of data, whether that’s text, images, or links, enriching your data sets effortlessly.
Exploring Different Web Scraping Tools
There are numerous web scraping tools available that cater to different user needs, from beginners to advanced data scientists. For those who prefer a visual interface, tools like Octoparse and ParseHub offer drag-and-drop functionality which simplifies the extraction process significantly. They allow users to capture data without needing extensive programming knowledge, making web scraping accessible to everyone.
On the other hand, advanced tools like Scrapy and Selenium offer more flexibility and control over web scraping tasks. Scrapy, being a framework, provides robust features that include data storage options, spider management, and handling requests and responses seamlessly. Meanwhile, Selenium can simulate browser behavior, allowing users to scrape content dynamically loaded with JavaScript—something traditional scraping methods struggle with.
Building Your Own Web Scraping Script
Building your own web scraping script can seem daunting at first, but once you grasp the core concepts, it becomes an exhilarating process. Starting with simple tasks can help build your confidence. Focus on trying to scrape data from a static website before moving to complex, dynamically loaded sites. Crafting your own scraper allows you to customize it to suit your specific needs, making data extraction even more efficient.
Moreover, building a personalized script can teach you valuable programming and data manipulation skills. You learn to debug errors, manage data formats like JSON or CSV, and even schedule scraping tasks using libraries like Schedule. This experience not only enhances your technical proficiency but also equips you with practical skills applicable in many data-centric roles.
Web Scraping Best Practices for Ethical Data Collection
Following ethical guidelines is critical in the web scraping domain. Always check the terms of service (ToS) of the websites you intend to scrape, as many prohibit automated data collection. Respecting those terms helps ensure that you are legally compliant and prevents potential issues like being blocked or facing legal action.
Additionally, consider the frequency and volume of your requests. Many websites employ IP rate limiting and other measures to detect and prevent scraping attempts. By implementing polite scraping techniques—such as limiting the number of requests per minute and using a pool of IP addresses—you can collect data efficiently without drawing attention.
Using API for Data Extraction Instead of Scraping
In some cases, using an API for data extraction may be more beneficial than traditional web scraping. APIs (Application Programming Interfaces) provide structured access to a website’s data and are specifically designed for external consumption, meaning you don’t have to worry about HTML changes or scraping ethics. For many platforms, accessing their API can be a faster and simpler route to obtain the information you need.
Most APIs come with documentation that explains how to authenticate, query, and receive data efficiently, often in formats such as JSON or XML. This structured data access allows developers to integrate the data seamlessly into applications, making it a preferred choice for many web developers thus highlighting the importance of knowing how to scrape websites and work with available APIs.
The Future of Web Scraping Technology
The field of web scraping is evolving with advancements in technology. As AI and machine learning continue to improve, web scraping tools are becoming more sophisticated. These advancements enable tools to better understand web structures, predict changes, and adapt dynamically to variations in HTML. The future promises more automated solutions that will make the data extraction process simpler, faster, and more efficient.
Furthermore, the growth of headless browsers and cloud-based scraping platforms is likely to revolutionize the industry. Headless browsers allow scripts to run without displaying a graphical user interface, enabling faster data retrieval and making it easier to handle complex web applications. As these technologies advance, the barriers to entry for effective web scraping will continue to decrease, opening new opportunities for businesses and individuals to leverage web data.
Integrating Web Scraping with Data Analysis
Once data is scraped, the next step often involves analysis. Integrating web scraping with data analysis allows users to extract insights from the collected information effectively. This process typically involves cleaning and organizing the scraped data, followed by application of statistical analysis or machine learning techniques to derive meaningful patterns and trends from it.
Popular programming languages such as Python and R provide excellent libraries that facilitate data analysis. For instance, Pandas in Python can be used to manipulate data structures post-extraction, making it easy to perform operations like merging and filtering. The ability to turn raw scraped data into actionable insights is what makes web scraping not just a technical skill but a powerful tool for decision-making.
Common Challenges in Web Scraping
Web scraping can come with its own set of challenges. One common issue is dealing with the dynamic nature of websites, which can change their layout and structure frequently. This change can break previously functioning scripts and may require ongoing maintenance. Additionally, websites may implement measures to prevent scraping, such as CAPTCHAs or bot detection plugins, which can complicate the data extraction process.
Another challenge is ensuring the legality and ethicality of web scraping activities. Scrapers need to be aware of copyright laws, data privacy regulations like GDPR, and the ethical implications of collecting site data. Understanding and navigating these legal constraints is crucial in maintaining responsible scraping practices while effectively achieving your data extraction goals.
Frequently Asked Questions
What is a web scraping guide and why is it important?
A web scraping guide provides step-by-step instructions on how to extract data from websites using various techniques. It is important because it helps users understand data extraction techniques, select appropriate web scraping tools, and implement best practices to ensure efficient and ethical scraping.
What are the best practices for Python web scraping?
When following a Python web scraping guide, the best practices include respecting robots.txt files, using time delays between requests, avoiding excessive scraping to prevent IP bans, and using libraries like Beautiful Soup and Scrapy for effective data extraction.
How do I choose the right web scraping tools?
Selecting the right web scraping tools depends on specific needs, such as ease of use, required features, and programming knowledge. A comprehensive web scraping guide can help you evaluate tools like ParseHub, Octoparse, or custom scripts written in Python based on your project requirements.
What are common data extraction techniques used in web scraping?
Common data extraction techniques in web scraping include HTML parsing, DOM manipulation, and using APIs. A solid web scraping guide will detail these techniques and show how they can be implemented using programming languages like Python.
Can you provide a brief overview of how to scrape websites effectively?
To effectively scrape websites, follow steps outlined in a web scraping guide: identify the target data, analyze the website structure, choose the appropriate scraping tool or library, write code to extract data, and ensure compliance with legal and ethical standards.
| Key Point | Details |
|---|---|
| Limitations of AI | AI cannot access external sites or scrape information directly. |
| Generating Scraping Scripts | AI can assist in creating web scraping scripts if details are provided. |
| Understanding Scraping | Provide specifics to receive tailored guidance on web scraping. |
Summary
This web scraping guide outlines the limitations of AI in accessing external websites directly, such as nytimes.com. While AI can generate scripts and provide instructions, any successful web scraping requires user input to determine the content needed. For effective web scraping, clear details and requirements are crucial, enabling tailored support in crafting your scraping scripts.


