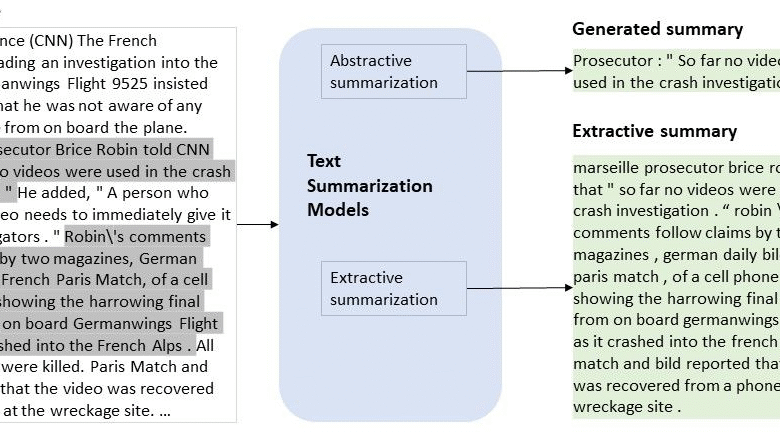
Content summarization is an essential skill in today’s fast-paced digital landscape, where information overload is a common challenge. The ability to distill complex articles into concise summaries can significantly enhance both comprehension and retention. By employing effective summarization methods, readers can save time while extracting key insights from various texts. In this guide, we share content summary tips and article summarization techniques that will empower you to summarize articles efficiently. Whether you’re a student, professional, or casual reader, mastering the art of summarizing content can elevate your understanding and communication of ideas.
Exploring the concept of summarizing information, we delve into various techniques that aid in condensing extensive texts into digestible formats. This process, often referred to as text reduction or content condensing, is crucial for anyone looking to grasp large volumes of data quickly. Effective methods for this practice not only enhance retention but also improve the clarity of the ideas being conveyed. Our discussion will focus on how to effectively summarize various forms of content while highlighting practical tips to elevate your summarization skills. By understanding these principles, you’ll be better equipped to navigate and synthesize information in today’s information-rich world.
The Importance of Content Summarization
Content summarization plays a crucial role in making information accessible and digestible for readers. As individuals are increasingly bombarded with vast amounts of data daily, a well-crafted summary can save time and spotlight key points efficiently. Effective summarization methods involve distilling the core message of an article while retaining essential detail, helping readers to grasp complex topics quickly without the need to read the entire text.
By utilizing effective content summary tips, individuals can enhance their reading experience and comprehension. For instance, when summarizing articles, focusing on the main argument, important facts, and conclusions is vital. This not only clarifies the author’s intent but also prepares the reader for further discussion or exploration of the topic. By honing these skills, one can create concise summaries tailored to various audiences, from professionals to students.
Techniques for Summarizing Articles Effectively
There are several article summarization techniques that can be employed to ensure brevity and clarity. One fundamental method involves identifying the thesis statement and main supporting points. This strategy highlights the backbone of the article, allowing the summarizer to filter out unnecessary information. Another technique is to use bullet points to outline significant details, which can also aid in quick reviews and easy reference later on.
Moreover, successful summarization often requires paraphrasing skills, where one can restate the core ideas in their own words. This not only indicates understanding but also prevents potential plagiarism. Following this, it’s advisable to conclude with insights or implications derived from the original content, providing a holistic view that encourages further exploration of the topic. These article summarization techniques not only simplify complex information but also enhance the reader’s ability to remember and reflect upon the content.
Frequently Asked Questions
What are the best tips for content summarization?
To effectively summarize content, focus on identifying key ideas, using concise language, and employing bullet points for clarity. Practice summarizing complex information into simplified versions while maintaining the core message. Utilizing content summary tips like highlighting main arguments and eliminating fluff can enhance readability.
How can I summarize articles effectively?
When summarizing articles, start by reading the entire piece to understand the main points. Note down important themes and arguments, then distill them into a clear, structured summary. Effective summarization methods include paraphrasing key sentences and avoiding unnecessary details.
What article summarization techniques should I use?
Popular article summarization techniques involve the use of the ‘who, what, when, where, why’ approach, as well as identifying the thesis statement and supporting points. Additionally, utilizing digital tools that specialize in summarization can aid in creating condensed content quickly.
What are effective summarization methods for academic texts?
Effective summarization methods for academic texts include annotating key sections, creating mind maps, and summarizing each paragraph to extract essential ideas. This method helps maintain the original intent while producing a shorter version, making the information accessible and easier to digest.
How do I condense content for better understanding?
To condense content for better understanding, analyze the original material to determine its main ideas, remove redundancy, and frame the content in simpler terms. Practicing summarizing content regularly can help improve clarity and effectiveness in conveying the central message.
| Key Point | Explanation |
|---|---|
| Limitations | Cannot access external websites directly, such as nytimes.com. |
| Assistance Provided | Can summarize or answer questions based on provided information. |
Summary
Content summarization is crucial for understanding complex topics quickly and effectively. While I cannot access external websites such as nytimes.com, I can assist you with summaries and questions regarding known information if you provide specific content or topics. This flexibility allows for focused assistance tailored to your needs, ensuring efficient communication and comprehension.