This week’s health news is buzzing with intriguing stories that could impact your wellness journey. From alarming Ozempic side effects to breakthroughs in vitamins for longevity, the latest health updates are essential for anyone looking to stay informed about their wellbeing. Scientists have also made strides in detecting ultraprocessed food consumption through blood tests, captivating the attention of health enthusiasts everywhere. As we navigate through various mental health trends, it’s imperative to be aware of how everyday choices affect our overall health. Join us as we dive into the top developments and insights shaping healthcare this week.
In the realm of healthcare and personal wellness, fresh insights are surfacing that highlight critical shifts in our understanding of health-related issues. Recent bulletins on innovative treatments and their implications on health have caught the public’s eye, shedding light on topics like the side effects associated with popular medications, as well as vitamins that may extend healthy lifespans. As societal interest grows regarding the consumption of processed foods and its effects on the body, various research findings provide a clearer picture of dietary impacts on our lives. Moreover, the evolving conversation around mental health continues to bring forward new strategies for well-being. Stay tuned for comprehensive coverage of these significant wellness developments!
Ozempic: Understanding the Side Effects
In recent discussions surrounding popular weight loss medications like Ozempic, many users are curious about their potential side effects. Research has indicated that GLP-1 receptor agonists can lead to various adverse effects, including dental issues such as tooth decay and gum disease. Dentists have begun to notice a correlation between patients using this medication and increased reports of oral health challenges, emphasizing the need for regular dental check-ups and proper oral care while on such prescriptions.
Moreover, while the spotlight is often on weight loss, it’s crucial to consider the holistic impact of Ozempic on overall health. With insights from health experts, users are encouraged to weigh the benefits against possible side effects critically. This includes not only oral health but also gastrointestinal issues and long-term hormonal alterations. Staying informed through the latest health news can empower individuals to make safer choices regarding their health journeys.
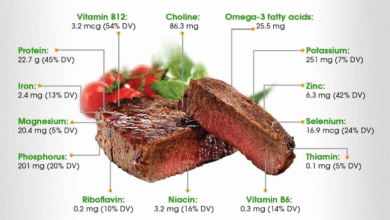
Vitamins for Longevity: A Breakthrough Study
Recent scientific studies have shed light on a common daily vitamin that shows promise in slowing biological aging. This groundbreaking research suggests that certain vitamins, when consumed in adequate amounts, can potentially enhance cellular health and longevity. The exploration into vitamins for longevity focuses on their role in boosting the immune system, improving brain function, and protecting against age-related diseases.
Incorporating these vitamins into a daily routine can become a simple yet effective way to foster long-term health. Nutritional experts recommend a diet rich in various vitamins, including D, E, and certain B vitamins, to combat oxidative stress and promote overall wellness. As individuals seek to improve their health, understanding these wellness developments is essential for achieving a longer, healthier life.
Scientific Advances in Food Detection: The Rise of Blood Tests and Wellness Awareness…
Frequently Asked Questions
What are the latest health updates regarding Ozempic side effects?
Recent health news has highlighted concerns about Ozempic and its potential side effects, including rumblings about dental issues. Patients using Ozempic should stay informed about the latest developments and consult healthcare providers if experiencing discomfort.
What vitamins for longevity are recommended in recent health news?
The latest wellness developments suggest that certain common daily vitamins may help slow biological aging. Research indicates that vitamins like Vitamin D and K could play crucial roles in promoting longevity, making them essential additions to a balanced diet.
What mental health trends are emerging from current health news?
Emerging mental health trends focus on holistic approaches and community-based support systems. Recent studies linked anxiety reduction to products like weighted blankets, emphasizing natural methods for fostering emotional well-being, as featured in the latest health updates.
How can blood tests detect ultraprocessed foods, according to health news?
Latest health updates reveal that scientists have developed methods to detect ultraprocessed foods in blood and urine tests. This advancement could lead to better dietary assessments and insight into how our nutrition affects overall health.
What are the implications of recent wellness developments on fitness trends?
Current wellness developments highlight innovative fitness trends that prioritize efficiency, such as trending workouts that promote fat burning without requiring intense exercise. These trends reflect a shift towards more accessible and sustainable fitness routines.
| Top Health News Stories | Summary | ||
|---|---|---|---|
| Is Ozempic ruining your teeth? Here’s what to know. | Common daily vitamin could slow biological aging, study suggests. | Scientists can detect junk food in blood and urine tests. | These developments highlight recent health news advancements. |
Summary
Health news is constantly evolving, with recent findings spotlighting potential risks and benefits in wellness. This week’s top stories included vital insights into GLP-1 medications, which some users may not be aware could affect dental health; the promise of common vitamins in slowing aging; and innovative blood tests that reveal dietary habits related to ultraprocessed foods. Staying informed on these topics is crucial for making informed health decisions.