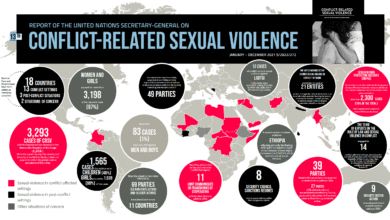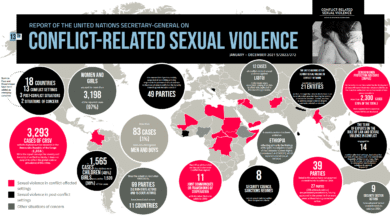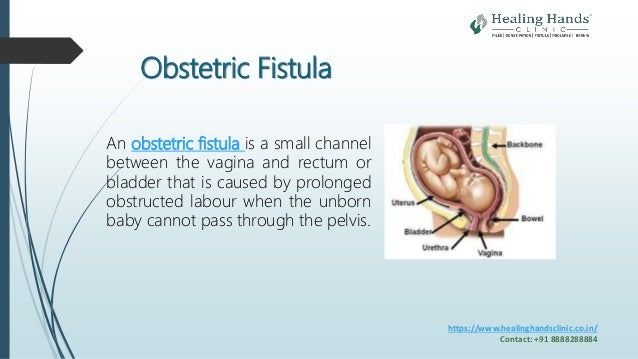
Obstetric fistula remains a critical yet often overlooked issue affecting over 500,000 women worldwide, primarily in low-resource settings. This debilitating condition stems from complications during childbirth, resulting in a fistula that can lead to chronic incontinence. However, despite its prevalence, it is important to recognize that obstetric fistula is fully treatable and preventable. Increasing awareness through fistula awareness programs and improving access to treatment for obstetric fistula can significantly change the lives of affected women. Ultimately, addressing global health disparities and enhancing women’s reproductive health can pave the way for a future without obstetric fistula, as we strive to empower those in dire need.
Known colloquially as childbirth injuries, conditions like obstetric fistula highlight severe gaps in maternal healthcare across various regions. These birth-related complications occur when prolonged labor leads to the development of abnormal openings between a woman’s reproductive organs and her bladder or rectum. The journey toward healing involves not only medical treatment but also societal support to combat loneliness and stigma. Efforts towards preventing obstetric complications through better education and increased healthcare access are essential. Additionally, initiatives aimed at contributing to women’s overall reproductive well-being must be prioritized to ensure an equitable healthcare landscape for all.
Understanding Obstetric Fistula: Causes and Consequences
Obstetric fistula is a devastating yet preventable condition that occurs during childbirth, particularly when women experience prolonged labor without adequate medical assistance. Most commonly seen in impoverished regions, particularly in the Global South, this condition creates a hole between the birth canal and either the bladder or rectum, leading to continuous leaking of urine or feces. The social consequences for women suffering from obstetric fistula are dire. They often face ostracism and isolation from their communities, leading to mental health challenges such as depression and anxiety.
The physical implications of obstetric fistula can also severely affect women’s reproductive health and overall quality of life. Many women, like Kambiré, endure years of discomfort and shame, often resulting in lower socioeconomic status as they may be unable to engage in income-generating activities. This form of suffering highlights the urgent need for comprehensive awareness campaigns and effective health interventions to address and prevent the occurrence of fistulas, focusing especially on improving maternal health services.
Preventing Obstetric Fistula: The Role of Midwives and Education
Preventing obstetric fistula is not just about providing surgical repairs; it’s imperative to focus on the underlying systemic issues that contribute to its prevalence. A critical component of prevention is ensuring that trained midwives are available to assist women during childbirth. The World Health Organization emphasizes that having skilled health personnel, especially midwives, significantly reduces the risk of complications during delivery. Unfortunately, the global shortage of midwives—over 900,000, with a significant proportion in Sub-Saharan Africa—exacerbates the problem and indicates a dire need for investment in women’s reproductive health training.
In addition to midwifery training, educational programs that empower women and inform them about their reproductive rights are crucial. Raising awareness about obstetric fistula can prevent stigma and encourage women to seek timely medical assistance. Initiatives like fistula awareness programs play a vital role in communities, enlightening both men and women about the condition and its treatment options. By elevating women’s voices and leadership capacities, these programs foster a supportive environment that can significantly reduce cases of obstetric fistula.
Global Health Disparities Affecting Women’s Reproductive Health
Global health disparities significantly impact women’s reproductive health, particularly in low-income countries where access to healthcare services is limited. Obstetric fistula remains a persistent issue, primarily due to lack of access to skilled birth attendants and emergency obstetric care. This disparity is further compounded by social factors such as gender inequality, poverty, and inadequate health facilities, which all contribute to the cycle of health crises faced by women in these regions.
Addressing global health disparities requires a multifaceted approach that includes investments in healthcare infrastructure and initiatives aimed at promoting gender equality. Organizations like UNFPA are making strides towards eliminating obstetric fistula by not only providing surgical support but also advocating for more resources to be allocated to women’s health. Increasing awareness and education around preventing obstetric fistula is pivotal in creating a healthier future for women around the globe.
Treatment Options for Obstetric Fistula: The Healing Journey
Fortunately, obstetric fistula is a highly treatable condition. Surgical intervention remains the most effective treatment, with thousands of women receiving assistance through initiatives led by organizations such as UNFPA. The repair surgery is not only life-transforming but often restores the dignity and health of women who have suffered in silence for years. Programs that offer holistic care—encompassing psychological support and vocational training—are crucial in helping women reintegrate into their communities post-treatment.
Many women report significant improvements in their overall wellbeing after receiving treatment for obstetric fistula. With successful repairs, women like Dah and Kambiré can return to daily life, pursue economic opportunities, and participate more fully in their communities. As awareness spreads about the treatability of obstetric fistula, the stigma surrounding it begins to diminish, empowering survivors on their journey to recovery.
Fistula Awareness Programs: Raising Voices and Changing Lives
Fistula awareness programs are vital in educating communities about obstetric fistula, its causes, and the importance of seeking timely medical care. Through community outreach, these programs not only aim to eliminate stigma but also inspire survivors to share their stories, fostering a supportive network for those who have lived with this condition. Empowering women to speak about their experiences not only validates their struggles but also encourages others to seek help without fear of shame.
Moreover, awareness initiatives can significantly influence public perception about women’s healthcare rights. By involving local leaders, families, and health professionals, these programs create a comprehensive understanding of the importance of women’s reproductive health. This multi-stakeholder approach not only enhances community education but also mobilizes resources to support ongoing prevention and treatment efforts for obstetric fistula.
Empowerment and Leadership among Fistula Survivors
Empowering women who have suffered from obstetric fistula to take on leadership roles within their communities can lead to transformative changes. As survivors share their stories and experiences, they not only raise awareness but also inspire other women facing similar challenges to seek help. By forming coalitions, these empowered women can advocate for better healthcare services and drive social change that prioritizes women’s health rights.
Leadership training and support programs for fistula survivors are crucial in building their confidence and fostering resilience. When women actively participate in decision-making processes regarding their health and community well-being, they contribute to a more supportive and inclusive society. This empowerment not only facilitates individual healing but also promotes collective advocacy for women’s reproductive health issues, leading to significant societal impact.
The Impact of Community Support on Fistula Recovery
Community support plays a pivotal role in the recovery and reintegration of obstetric fistula survivors. When women receive treatment, the subsequent emotional and social support from their families and communities can greatly influence their healing process. Building strong support networks helps to diminish feelings of isolation and stigma that many survivors face, encouraging them to reinvest in their communities and rebuild their lives.
Engaging communities in supporting fistula survivors offers an opportunity for holistic recovery. This can include vocational training, financial literacy programs, and access to healthcare resources, enabling women to regain their independence and contribute economically. Through collaborative efforts, communities can create an environment where women are no longer defined by their past experiences, but rather celebrated for their strength and resilience.
Global Commitment to End Obstetric Fistula by 2030
The global commitment to end obstetric fistula by 2030 is ambitious yet achievable with the right strategies and support systems in place. International organizations, governments, and local NGOs play a vital role in scaling up efforts to provide comprehensive maternal healthcare. By focusing on preventive measures, such as training skilled birth attendants and expanding access to emergency care, the rates of obstetric fistula can be significantly reduced.
Additionally, fostering partnerships and collaboration among stakeholders can accelerate progress towards this goal. By pooling resources, leveraging expertise, and sharing best practices, significant strides can be made in improving women’s reproductive health worldwide. The collective commitment to eradicate obstetric fistula is not just about addressing a health crisis; it’s about ensuring that women everywhere have access to the care, education, and rights they deserve.
The Future of Women’s Reproductive Health Initiatives
As the world continues to grapple with issues surrounding women’s reproductive health, initiatives focused on preventing and treating obstetric fistula must remain a priority. Innovations in healthcare, combined with robust advocacy efforts, can lead to improved health outcomes for women globally. New strategies, such as telemedicine and mobile health units, can bridge the gaps in care delivery and ensure that women have access to the services they need.
Looking ahead, the focus should not only be on treatment but also on preemptive measures that address the root causes of obstetric fistula. Engaging communities in meaningful discussions about reproductive rights, gender equality, and maternal health will be paramount in reshaping societal norms and ensuring that every woman receives the care she deserves. The future of women’s reproductive health initiatives is bright, filled with potential as long as we remain steadfast in our commitment to universal health access and the eradication of obstetric fistula.
Frequently Asked Questions
What is obstetric fistula and how does it affect women’s reproductive health?
Obstetric fistula is a medical condition characterized by a hole between the birth canal and the bladder or rectum, resulting from prolonged or difficult childbirth. It affects women’s reproductive health by causing incontinence, which leads to social isolation, depression, and poverty. Given its prevalence, especially in the Global South, addressing obstetric fistula is crucial for improving women’s overall health.
What are the treatment options available for obstetric fistula?
Treatment for obstetric fistula typically involves surgical repair, which has been shown to be highly effective. Organizations like UNFPA have supported numerous surgical repairs, providing women with the necessary medical assistance to restore their health. Early intervention can greatly improve outcomes and empower women to regain control over their lives.
How can communities participate in preventing obstetric fistula?
Preventing obstetric fistula requires collective community action. Education on reproductive health, access to skilled midwives, and the promotion of safe childbirth practices are vital. Community awareness programs can also help reduce stigma and inform women about available resources and treatment options.
What impact do global health disparities have on obstetric fistula?
Global health disparities significantly contribute to the persistence of obstetric fistula, particularly in resource-limited settings. The shortage of skilled midwives and access to quality maternal healthcare services means that many women face higher risks during childbirth, resulting in increased cases of obstetric fistula. Addressing these disparities is essential for eliminating this condition by 2030.
How do fistula awareness programs contribute to women’s health?
Fistula awareness programs play a crucial role in educating communities about obstetric fistula and its treatability. By raising awareness, these programs empower women, reduce stigma, and encourage those affected to seek medical help. Educated communities are more likely to support prevention strategies and improve overall women’s reproductive health.
What role do midwives play in preventing obstetric fistula?
Midwives are essential in preventing obstetric fistula as they provide critical support during labor and delivery. They are trained to recognize complications and facilitate safe childbirth practices, significantly reducing the risk of fistulas. Addressing the global shortage of midwives, particularly in Sub-Saharan Africa, is vital for improving maternal health outcomes.
How can empowering women help eliminate obstetric fistula?
Empowering women is key to eliminating obstetric fistula as it enhances their voice, leadership, and access to healthcare services. When women are informed about their reproductive rights and health options, they are better equipped to advocate for themselves and their communities, leading to improved health outcomes and reduced incidence of obstetric fistula.
| Key Point | Details |
|---|---|
| Obstetric Fistula Statistics | Affects over 500,000 women globally, primarily in the Global South. |
| Treatment Duration | Women may endure obstetric fistula for years, undergoing multiple surgeries; for example, Dah suffered for 16 years. |
| Root Causes | Often caused by prolonged or difficult childbirth, leading to social isolation and economic hardship. |
| UNFPA Goals | The United Nations Population Fund aims to eliminate obstetric fistula by 2030. |
| Prevention and Education | Midwives are essential for prevention; there is a current shortage of over 900,000 midwives, particularly in Sub-Saharan Africa. |
| Community Involvement | Survivors are encouraged to form networks to raise awareness and reduce stigma around obstetric fistula. |
| Empowerment of Women | Empowering women through education and support is vital in the fight against obstetric fistula. |
Summary
Obstetric fistula is a preventable and treatable medical condition that affects hundreds of thousands of women worldwide, particularly in developing regions. It arises predominantly from prolonged labor during childbirth and is linked to severe physical and psychological consequences. The fight against obstetric fistula must emphasize education, the empowerment of women, and increased access to skilled midwives to ensure that no woman has to suffer in silence. Initiatives led by organizations like UNFPA aim to create a future free of obstetric fistula, highlighting the importance of community support and medical intervention. By 2030, with adequate resources and awareness, we can help eradicate this silent crisis.