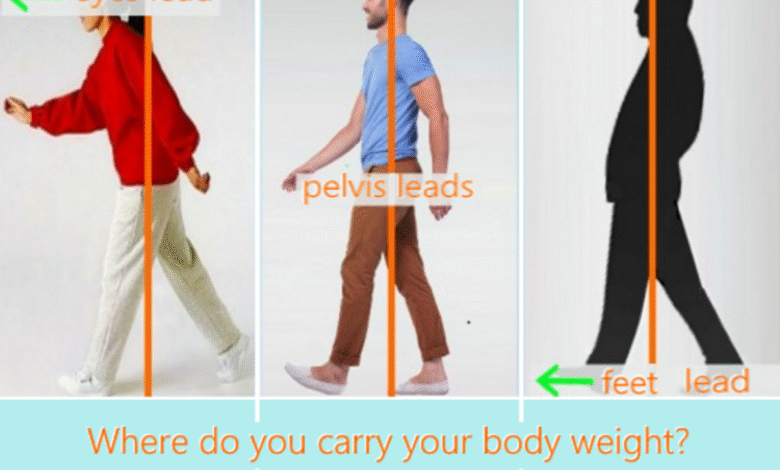
Walking improves back pain, a finding supported by recent research that highlights the connection between regular physical activity and chronic back pain relief. Studies show that participants engaging in daily walks of over 100 minutes experience a significant 23% reduction in the risk of lower back pain compared to those who walk less than 78 minutes. This evidence underscores the benefits of walking, particularly for individuals suffering from walking and lower back pain, as consistent movement can facilitate recovery and minimize discomfort. Physical activity for back pain not only aids in strengthening muscles that support the spine but also enhances overall mobility. By incorporating more walking into daily routines, people can take proactive steps to reduce back pain by walking, leading to improved health and well-being.
The act of strolling can serve as a powerful remedy for those grappling with persistent discomfort in their back. Engaging in simple forms of exercise, such as walking, has been shown to alleviate symptoms linked to chronic back issues. Various forms of mild aerobic activities, especially walking, can play a crucial role in alleviating lower back discomfort. Improving one’s physical fitness through these gentle movements promotes better posture and strengthens supportive muscle groups. Therefore, adopting a regular walking regimen can be an effective strategy to combat and manage back pain.
The Role of Walking in Back Pain Management
Walking is often hailed as a simple yet effective form of physical activity that can significantly aid in back pain management, especially chronic lower back pain relief. According to a recent study published in JAMA Network Open, increased walking duration has been closely linked to a reduction in the incidence of chronic back pain. Specifically, participants who walked for over 100 minutes a day experienced a remarkable 23% reduction in back pain compared to those who walked less than 78 minutes. This highlights that even moderate, accessible physical activity such as walking can yield substantial benefits for those suffering from debilitating back issues.
Moreover, walking not only offers the immediate benefit of pain reduction but also promotes overall physical well-being. Engaging in regular walking can improve flexibility, strengthen core muscles, and enhance posture—all of which are crucial for preventing further back pain. As Dr. Arthur L. Jenkins III points out, maintaining an active lifestyle through walking can be extremely beneficial, provided it is done safely and in alignment with one’s orthopedic capabilities. Therefore, incorporating walking into one’s daily routine serves not only as a remedy for pain but as a proactive approach to long-term spinal health.
How to Effectively Incorporate Walking for Back Pain Relief
If you’re looking to integrate walking into your routine for chronic back pain relief, it’s essential to start gradually. Begin with shorter walks and slowly increase both the duration and intensity as your body adjusts. For instance, aim to walk for about 10-15 minutes initially and gradually build up to the recommended 100 minutes per day, which the research suggests could lead to significant reductions in chronic pain risk. Additionally, consider the terrain; walking on softer surfaces, like grass or dirt trails, can reduce stress on your back compared to harder surfaces like concrete.
Incorporating techniques such as proper posture and engaging your core while walking can also enhance the benefits. As Dr. Jenkins mentions, utilizing your core muscles during physical activity helps improve stability and alignment, which can mitigate further pain. Moreover, setting realistic goals and tracking your progress can sustain motivation. It’s helpful to maintain a record of how much you walked each day and any changes in your pain levels. This approach not only provides immediate feedback on your walking regimen’s efficacy but can also help you stay dedicated to ongoing physical activity and back pain management.
The Mental and Physical Benefits of Walking
Beyond physical rehabilitation, walking offers a myriad of mental health benefits that contribute to an overall sense of well-being, which can be particularly significant for individuals dealing with chronic pain. Engaging in regular walking sessions can reduce stress and anxiety levels, which in turn can alleviate some of the mental burdens associated with ongoing pain. As a low-impact form of exercise, walking allows individuals to gradually regain confidence in their movement, regain a sense of control over their bodies, and create a positive reinforcement loop of physical activity leading to less pain and better mental health.
Moreover, the beauty of walking lies in its accessibility; it requires no specialized equipment and can be done in various environments, making it easier for most people to engage consistently. The feel of fresh air and the sights and sounds of nature can invigorate the mind, enhancing the experience of physical activity. As such, encouraging senior communities and workplaces to build walking programs and initiatives can be a vital strategy for public health, emphasizing walking as an effective mode of physical activity that generously contributes to both back pain relief and overall quality of life.
Why Regular Foot Movement Matters for Lower Back Health
Regular foot movement, facilitated by activities like walking, plays a crucial role in maintaining lower back health. The act of walking engages various muscle groups, promoting flexibility and strength in the lower body, which is vital for spinal stability. Strengthening the legs, hips, and core through consistent walking can provide the necessary support for the lumbar spine, ultimately reducing the strain that often exacerbates lower back pain. Furthermore, a study indicated that individuals who maintained a higher volume of walking exhibited a significantly lower risk of developing chronic lower back issues.
In addition to strengthening muscles, regular movement encourages the circulation of blood and nutrients to spinal structures, aiding in recovery and reducing inflammation around spinal joints and muscles. It can also help regulate body weight, preventing the excess load that can contribute to back pain. These interconnected benefits underscore the importance of establishing a walking regimen that prioritizes not just the act of movement but also the nurturing of overall spinal health, emphasizing how essential regular foot movement is for preventing and managing lower back pain.
Public Health Initiatives to Promote Walking
With the compelling evidence suggesting that walking can significantly reduce chronic lower back pain, it becomes essential for public health initiatives to promote walking as a primary strategy for pain management. Cities and communities can develop safe, accessible walking paths and programs that encourage residents to incorporate walking into their daily routines. Moreover, campaigns that educate individuals on the enormous benefits of engaging in regular physical activity, such as walking, can lead to a comprehensive shift in lifestyle habits that favor better health outcomes.
Additionally, workplace wellness programs can initiate walking challenges or encourage walking meetings to integrate more movement into the average workday. By fostering environments that support and encourage walking, public health officials can not only help alleviate the prevalence of chronic back pain but also contribute to better overall public health. The continued promotion of walking as a primary activity for enhancing physical health provides communities with opportunities to collectively reduce the rates of chronic conditions, such as back pain, while simultaneously encouraging a culture of active living.
Understanding the Link Between Walking and Chronic Pain
To fully grasp the undeniable link between walking and chronic back pain relief, it is essential to acknowledge the mechanisms through which walking affects the body. Engaging in regular walking promotes the release of endorphins, the body’s natural pain relievers, which can diminish the perception of pain and enhance mood. Research consistently shows that physically active individuals report less pain compared to sedentary individuals, asserting that incorporating habitual walking can change one’s approach to managing pain.
Furthermore, walking aids in maintaining spinal alignment and reducing muscular tension. As the body becomes accustomed to regular movement, the associated muscle tone supports the spine more effectively, leading to reductions in pain severity over time. Therefore, understanding this connection can help individuals take proactive steps in their pain management strategies by including walking as a vital component of their daily lives.
The Importance of Customizing Your Walking Regimen
When it comes to walking for lower back pain relief, the importance of customizing one’s regimen cannot be overstated. Every individual has different levels of fitness, types of back pain, and limitations. Therefore, tailoring your walking program based on personal capabilities, preferences, and pain levels is crucial. Consulting a healthcare professional before starting a new walking regimen can provide valuable insights and modifications to meet specific needs while preventing potential injuries.
Moreover, personalizing your walking experience can make it more enjoyable, which is essential for maintaining consistency in physical activity. Whether that involves choosing scenic routes, varying the types of surfaces walked on, or incorporating walking with social elements, customizing your approach promotes sustained engagement. Striking a balance that feels both challenging and achievable helps develop lifelong healthy habits essential for pain management and overall well-being.
Staying Safe While Walking for Pain Relief
While walking can significantly help alleviate chronic back pain, it is imperative to stay safe while embarking on this physical journey. Wearing the right footwear is critical to support your feet and reduce the risk of injury. Well-cushioned, supportive shoes can make a considerable difference in comfort levels, especially for individuals with existing back pain conditions. Additionally, choosing appropriate walking gear and ensuring proper hydration is essential, particularly during long walks or in warmer weather.
It’s also vital to listen to your body; if pain worsens during or after walking, take it as a sign to modify the duration or intensity of your walks. Gradually increasing your walking time can prevent overexertion and ensure that you reap the benefits of walking to relieve back pain without exacerbating your condition. By incorporating safety precautions and tuning into your body’s cues, you can enjoy the numerous benefits of walking while effectively managing lower back discomfort.
Complementing Walking with Other Therapeutic Strategies
While walking stands out as a powerful tool for chronic back pain relief, complementing it with other therapeutic strategies can enhance overall effectiveness. Engaging in stretching or yoga exercises to improve flexibility and strengthen muscles is an excellent way to support walking routines. These practices can aid in loosening tight muscles and improving range of motion, allowing individuals to walk more comfortably and effectively. Additionally, integrating strength training can provide the necessary support to the spine, enhancing resilience against pain.
Furthermore, several individuals may benefit from working with a physical therapist who can develop a tailored regimen that combines walking alongside other treatment modalities. Therapy can ensure that individuals not only walk effectively but also understand which movements to avoid to prevent pain flare-ups. By viewing walking not just as a standalone exercise but as part of a comprehensive, multifaceted approach to pain management, those suffering from chronic back pain can maximize their chances of living a pain-free life.
Frequently Asked Questions
How does walking improve back pain for those suffering from chronic back pain relief?
Walking is an accessible form of physical activity that can significantly help in chronic back pain relief. A recent study found that individuals who walked for more than 100 minutes a day had a 23% lower risk of experiencing lower back pain compared to those who walked less than 78 minutes. This practice promotes mobility, strengthens muscles, and enhances overall posture, all contributing to reduced back pain.
What are the benefits of walking for lower back pain relief?
The benefits of walking for lower back pain relief are substantial. Walking helps improve flexibility, strengthens core muscles, and promotes blood circulation, which can reduce inflammation and pain. Regular walking, especially over 100 minutes per day, is associated with a lower risk of chronic lower back pain, making it a beneficial activity for those seeking pain relief.
Can walking and lower back pain be effectively managed together?
Yes, walking and lower back pain can be effectively managed together. Engaging in regular walking can help alleviate pain symptoms and enhance mobility. Studies suggest that maintaining a daily walking routine can lower the risk of chronic back pain, making it an essential part of pain management strategies for those suffering from back issues.
How does physical activity for back pain include walking as a key component?
Physical activity for back pain includes walking as a key component due to its low-impact nature and accessibility. The findings from a research study support that walking can reduce the occurrence of chronic lower back pain, encouraging public health initiatives to promote walking as part of a healthy lifestyle to combat back pain.
Is it true that you can reduce back pain by walking regularly?
Absolutely! Regular walking can help reduce back pain significantly. Research indicates that higher daily walking volumes are linked to lower risks of chronic lower back pain. By incorporating longer walks into your daily routine, you can help strengthen your back muscles and improve your overall posture, leading to pain reduction.
| Key Points |
|---|
| Research in Norway finds that longer walks can improve chronic low back pain. |
| The study measured daily walking volume and intensity among over 11,000 participants over 20 years old. |
| Over one-quarter of Americans suffer from chronic lower back or sciatic pain. |
| Walking for more than 100 minutes daily lowers back pain risk by 23% compared to walking less than 78 minutes. |
| Walking intensity is important, but walking volume has a more significant impact on back pain risk. |
| Public health strategies promoting walking could help reduce chronic lower back pain occurrences. |
| Dr. Arthur L. Jenkins III advises patients to engage their core while walking for better posture and strength. |
Summary
Walking improves back pain, as indicated by recent research showing that regular walking can significantly reduce the risk of chronic lower back pain. Engaging in longer walks—specifically over 100 minutes a day—has been linked to a notable decrease in pain risk, supporting the idea that physical activity is beneficial for maintaining back health. With a significant portion of the population suffering from chronic pain, incorporating walking into daily routines could be an effective strategy for pain management. Furthermore, focusing on the intensity and duration of walks may help individuals personalize their exercise programs to maximize benefits.